需要予測とシミュレーションによる在庫および発注方式の適正化
在庫管理と発注方式の適正化は、企業にとって重要な課題です。
適切な在庫管理と発注方式を実施することで、企業は適切な在庫レベルを維持し、生産性を最適化し、同時にコストを削減することができます。しかし、適切な在庫管理と発注方式を決定するには、正確な需要予測とシミュレーションが必要です。
本記事では、需要予測とシミュレーションにより、在庫管理と発注方式を適正化する方法を探究します。具体的には、どのような需要予測とシミュレーション手法が最適か、どのような情報が必要か、どのような在庫管理と発注方式が最適かを検討します。
目次[非表示]
問題設定
図1は、ある商品の過去1年間の仕入数量・出荷数量・在庫の推移を示しています。
年度の前半は欠品回避のために発注量を多めにした結果、在庫を過剰に持ってしまっています。年が明けて1月から発注量を減らして持ちすぎた在庫の調整を行っています。
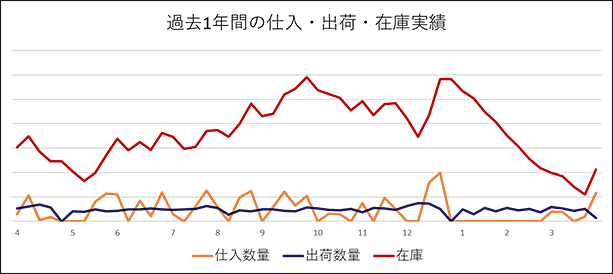
図1 ある商品の過去一年間の仕入数量・出荷数量・在庫の推移
在庫管理を行う上で、需要側や供給側の変動を吸収し欠品が発生しないように「安全在庫」を余剰在庫として持ちますが、安全在庫を過剰に持ってしまうと以下のような問題が発生します。
・在庫管理費の増加
・置き場の不足
・期限切れまたは陳腐化による廃棄コストの増加
安全在庫を過剰に持ってしまう理由としては、何らかの指標に基づいて発注する仕組みがない、欠品を恐れて俗人的に発注量を決めている、などが挙げられます。
本稿では、在庫を適正化するための3つのステップをご紹介します。
ステップ1: 精度の高い需要予測を行う
ステップ2: 需要予測を元に安全在庫レベルと発注数量の決定方法を策定する
ステップ3: 策定した決定方法が不確定要素から受ける影響を検証する
ステップ1:精度の高い需要予測
近年、プログラミング不要で自動的に高精度な需要予測モデルを作成するクラウドサービスが出現しています。AIモデルの作成・運用が可能なAI・機械学習プラットフォーム「DataRobot」は、入力した学習データから需要パターンを学習し、数千のアルゴリズムから最適なものを自動選択することができます。
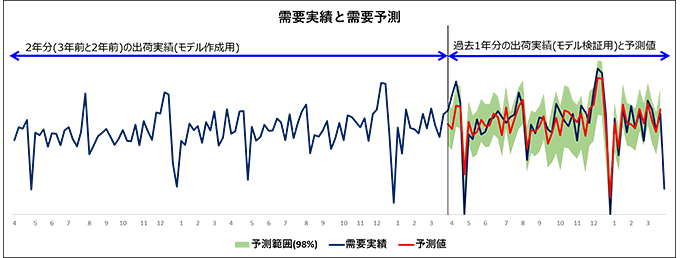
図2 DataRobotを使って出力した需要予測
図2はDataRobotが選択したモデルを使って出力した需要予測値です。98%の予測範囲の中に出荷実績が収まっており、自動で精度の高いモデルが作成されていることが分かります。
ステップ2:需要予測を元に安全在庫レベルと発注数量の決定方法を策定する
次に、ステップ1で求めた需要予測値を使って、安全在庫と発注量の決定方法を検討します。まずは在庫理論に基づいて、安全在庫と発注量を計算し、在庫がどうなるかを机上でシミュレーションしてみます(ケーススタディ1)。発注間隔は週単位(毎週末)、発注リードタイムは2週間(週末発注後、翌々週末に入庫)とします。
表1 在庫理論の数式

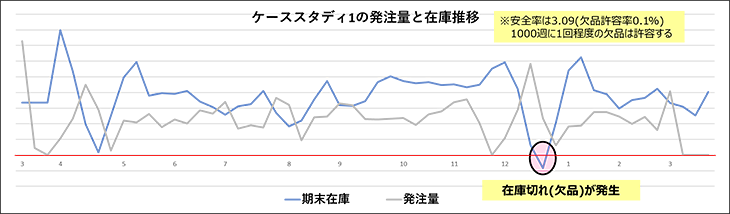
図3 在庫理論に基づき安全在庫と発注量を決定したときの在庫シミュレーション結果
安全在庫の安全率は3.09に設定しています。安全率3.09は欠品許容率が0.1%、つまり1000週に1回程度の欠品は許容するという高いレベルの設定値です。にもかかわらず1年分のシミュレーションで欠品が発生するという結果になりました(図3)。
これは在庫理論の「予測誤差は正規分布に従う」「予測誤差は時間軸に依存しない」という前提条件が、必ずしも成立しないことに起因します。
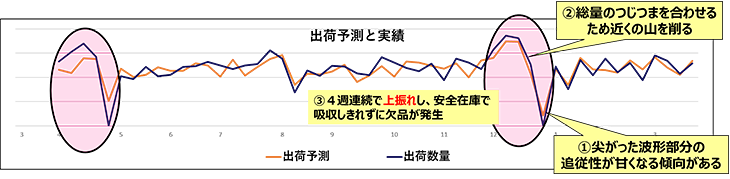
図4 今回の需要予測モデルの予測誤差の傾向
図4は今回作成した需要予測モデルの予測誤差の傾向を表しています。今回作成した需要予測モデルは尖った波形部分の追従性が甘くなる(予測値が多めになる)傾向があるため、その前の数週の予測数量が減らされ実績が上振れするという誤差傾向になっています。その影響でケーススタディ1では出荷が予測に対して数週上振れとなり、安全在庫で吸収できずに欠品が発生するという試算になっています。
欠品発生に対する改善策は3つあります。1つ目は安全在庫をさらに増やすことですが、在庫適正化の観点から望ましくありません。2つ目は予測モデルを在庫理論の前提に従う誤差傾向に修正することですが、これは専門性を要する作業のため簡単ではありません。3つ目は発注量を調整する方法です。
図3ケーススタディ1の発注量と在庫のグラフを見てみますと、欠品発生の3週前の発注量が0になっているということが分かります。そこで最低発注量を0より増やしてみて改善するかどうかを検討します。
最低発注量は需要予測の出力値「予測範囲98%」の範囲を参考に、その下限値を最低発注量として試算します(ケーススタディ2)。なお通常は上限値を採用しますが、ここでは在庫適正化の観点から数量の少ない下限値を用いて検証しております。
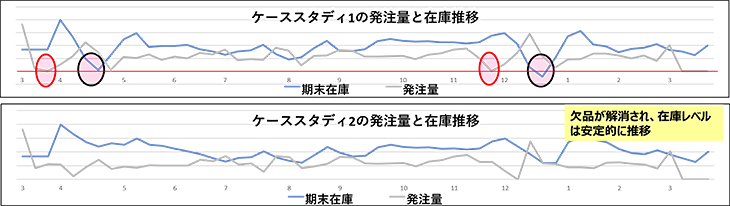
図5 ケーススタディ1と、最低発注量を見直したケーススタディ2との比較
図5より、ケーススタディ2では、ケーススタディ1に比べて、欠品がなくなり在庫も安定的に推移することが分かりました。
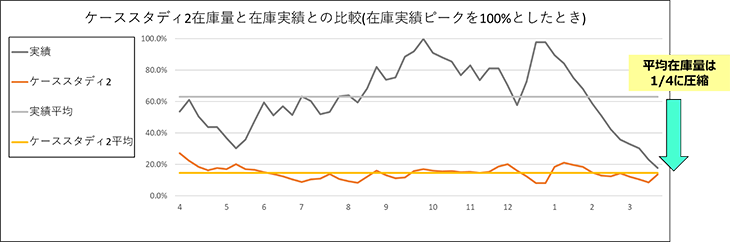
図6 ケーススタディ2と実績における、在庫量の比較
ケーススタディ2と実績とを比較すると、平均在庫量は1/4に圧縮できることが分かりました。
ステップ3: 策定した決定方法が不確定要素から受ける影響を検証する
安全在庫を持つ目的は、需要や供給の変動を吸収し機会損失(欠品)を減らすためです。ステップ2の机上検討では1年分のデータでしか検証しておらず、また不確定要素の影響も考慮していないため、机上検討の結果をもって安全在庫や発注方式が適正であることを保証するには不十分です。
ステップ3では、シミュレータを使って不確定要素による影響を評価します。リードタイムは1~5週までばらつきがあるものとします。また、需要のばらつきも実績のプラスマイナス10%のケースとプラスマイナス20%のケースを想定し、100年分のシミュレーションを行います。
表2 在庫シミュレーションによる欠品発生および在庫レベルの評価
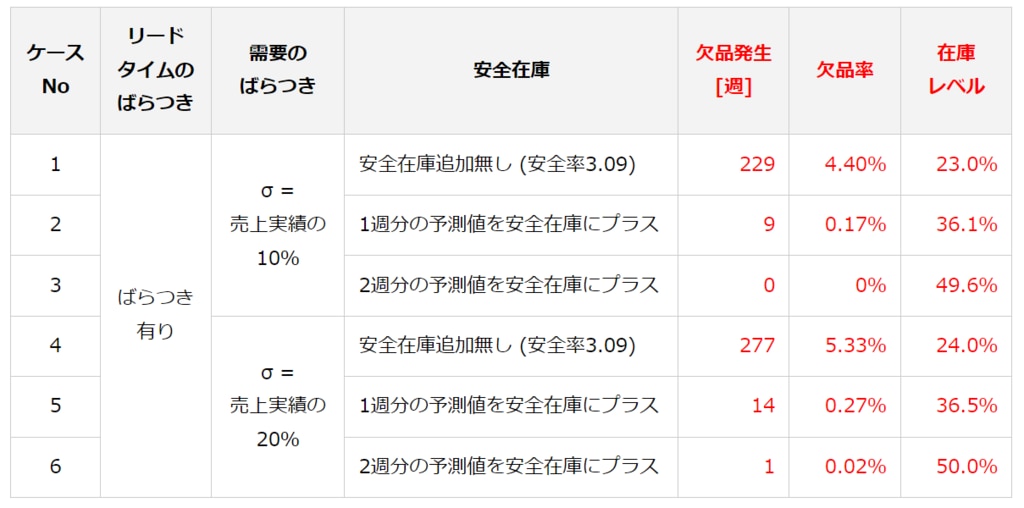
安全在庫なしのケース(ケースNo.1およびNo.4)では2~3回/年の欠品が発生するという結果が得られました。そこで安全在庫をプラスしたケースを実行したところ、2週分の需要予測値を安全在庫にプラスしたケース(ケースNo.3およびNo.6)では、ほぼ欠品が抑えられ、在庫レベルも実績の半分に抑えられることが検証できました。
本ソリューション詳細に関しましては下記資料をご覧ください。
伊藤忠テクノソリューションズのIntelligentTwinサービス

伊藤忠テクノソリューションズでは、『IntelligentTwinサービス』を展開しています。
製造業を中心に多くの企業がデータの蓄積・活用先としてデジタルツインに積極的に取組んでいますが、「使用するデータが不足している」「取得できないデータがある」「分析技術が足りない」などの課題が挙げられます。
IntelligentTwinサービスでは、これらの課題に対して、AI、シミュレーション、数理最適化を組み合わせて、最適な価値を提供します。
また、生産性向上や新規設備投資計画、人員配置最適化などの課題に対しては、適切な手法の選定から運用フェーズでのモデル精度維持まで、さまざまな形でご支援いたします。

まとめ
本稿では、精度の高い需要予測結果から安全在庫および発注方式を机上検討し、さらに不確定要素をシミュレーションで検証することで、欠品率および在庫レベルの両方を適正化できることをご紹介しました。
実際には不良率や賞味期限など考慮すべき条件が多岐に渡りますが、それらもシミュレーション要素に追加して検証することが可能です。これらの仕組みを活用することで、ビジネス環境が変わった場合でも持続的に在庫レベルの適正化が可能になります。
【関連記事】